

Continous deployment is all the rage; Devops is the new shiny. Since I have an Interlok hammer, everything is a nail. As a thought experiment I decided to use an Interlok instance as part of a pipeline to auto-restart+update other instances whenever a git push event happened for a couple of repositories that I work on frequently. Yep, definitely ![]() time.
time.
Ultimately you’re going to end up with something that logically works like this :
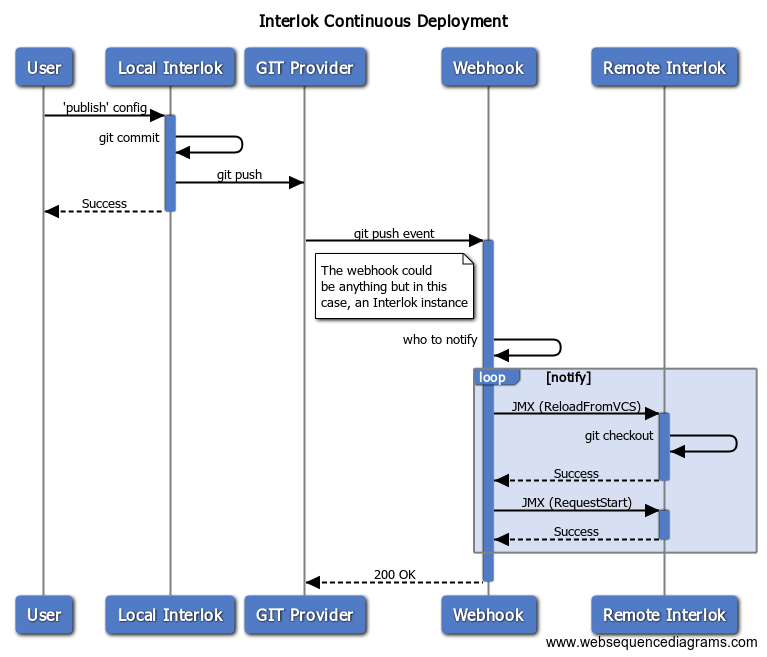
The remote Interlok instance
You’ll need to have JMX enabled on your target Interlok instance; and also have it access configuration stored in version control (vcs-git). Once you’ve successfully provisioned that instance so that it clones the git repo, and starts up successfully then you can start working on the webhook instance. The Interlok config itself doesn’t actually need to do anything; it just needs to be valid so that the remote instance can start; you can probably start with a simple “hello-world” adapter (e.g. https://github.com/adaptris-labs/interlok-hello-world/blob/master/src/main/interlok/config/adapter.xml). Choose your adapter-unique-id wisely, as you probably don’t want to change that unncessarily as that just causes more complexity.
You could use any git hosting provider (for instance github or bitbucket; other repositories are available of course) that supports webhooks. Just setup the webhook and make sure that it’s enabled for push events; point it at your publicly accessible Interlok instance.
The webhook instance
Your webhook adapter needs to be publicly accessible so that github can POST data to it; all we need to do is to receive the push, figure out which of the remote adapters it refers to, and use JMX to control it. It’ll need to be JSON enabled as that’s what github sends us.
Essentially it would look like this; my proof of concept just had everything configured as part of a CSV file (which was accessed via csvjdbc + jdbc-data-query-service); how the repository/jmx bindings are stored are really up to you.
<standard-workflow>
<unique-id>Webhook</unique-id>
<consumer class="jetty-message-consumer">
<unique-id>github-webhook</unique-id>
<destination class="configured-consume-destination">
<destination>/github/*</destination>
<configured-thread-name>github-webhook</configured-thread-name>
</destination>
<parameter-handler class="jetty-http-parameters-as-metadata"/>
<header-handler class="jetty-http-headers-as-metadata">
<header-prefix>github_</header-prefix>
</header-handler>
</consumer>
<service-collection class="service-list">
<services>
<add-metadata-service>
<metadata-element>
<key>CD_ENABLED</key>
<value>false</value>
</metadata-element>
</add-metadata-service>
<!-- Get the reponame -->
<json-path-service>
<json-path-execution>
<source class="constant-data-input-parameter">
<value>$.repository.name</value>
</source>
<target class="metadata-data-output-parameter">
<metadata-key>gitRepo</metadata-key>
</target>
</json-path-execution>
</json-path-service>
<!-- Based on the repo name, we can look up stuffs from our database
Let's assume that the database table contains the following additional columns.
'CD_ENABLED' == true | false
'JMX_URL' == the JMX url (service:jmx:jmxmp://172.21.21.21:5555)
'INTERLOK_UID' == the adapter name.
-->
<jdbc-data-query-service>
<connection class="shared-connection">
<lookup-name>csv-jdbc</lookup-name>
</connection>
<statement-creator class="jdbc-configured-sql-statement">
<statement>SELECT * FROM repos where REPO_NAME = '%message{gitRepo}'</statement>
</statement-creator>
<result-set-translator class="jdbc-first-row-metadata-translator">
<metadata-key-prefix></metadata-key-prefix>
<separator></separator>
</result-set-translator>
</jdbc-data-query-service>
<branching-service-collection>
<first-service-id>enabledForCD<first-service-id>
<services>
<metadata-value-branching-service>
<unique-id>enabledForCD</unique-id>
<metadata-key>CD_ENABLED</metadata-key>
<default-service-id>NoOp</default-service-id>
<value-matcher class="equals-value-matcher"/>
<metadata-to-service-id-mappings>
<key-value-pair>
<key>true</key>
<value>reloadAndRestart</value>
</key-value-pair>
</metadata-to-service-id-mappings>
</metadata-value-branching-service>
<service-list>
<unique-id>reloadAndRestart</unique-id>
<services>
<jmx-dynamic-operation-service>
<jmx-service-url>%message{JMX_URL}</jmx-service-url>
<object-name>com.adaptris:type=Registry,id=AdapterRegistry</object-name>
<operation-name>reloadFromVersionControl</operation-name>
</jmx-dynamic-operation-service>
<jmx-dynamic-operation-service>
<jmx-service-url>%message{JMX_URL}</jmx-service-url>
<object-name>com.adaptris:type=Adapter,id=%message{INTERLOK_UID}</object-name>
<operation-name>requestStart</operation-name>
</jmx-dynamic-operation-service>
</services>
</service-list>
<service-list>
<unique-id>NoOp</unique-id>
</service-list>
</services>
</branching-service-collection>
<standalone-producer>
<producer class="jetty-standard-response-producer">
<status-provider class="http-configured-status">
<status>ACCEPTED_202</status>
</status-provider>
<response-header-provider class="jetty-no-response-headers"/>
<send-payload>false</send-payload>
</producer>
</standalone-producer>
</services>
</service-collection>
</standard-workflow>
And finally…
Now you can start making changes to your remote Interlok configuration via your preferred method; the Interlok UI with a vcs-profile; vi, notepad++, whatever you like. Publish via the UI; or git commit + git push and your changes will be automagically pushed into your remote Interlok instance.
Could you use something like this to actually run your continuous deployment pipelines? You would make a decision based on what your business needs are; we’re using an Interlok based webhook to drive our public docker image builds (adaptris/interlok:snapshot + adaptris/interlok:snapshot-alpine) after our snapshot releases are published into our artefact repository. After all, everything needs integration.