

As a general rule, we recommend that failed messages are stored somewhere that always exists like the filesystem; this is always a bit more predictable, having to error handle your error handling can lead to a rabbits’ warren of twisty little passages all alike. There are times, when you can’t do that because the filesystem isn’t appropriate (e.g. if you’re running in a container, and you haven’t got permanent volumes); you still want to write the messages into a permanent store, and retry them on demand.
We had a situation where a customer wanted to store all the failed messages in S3. Sadly failed-message-retrier only works with polling consumer implementations and our S3 integration is service based. It is still possible by having an additional channel and a normal filesystem based retrier.
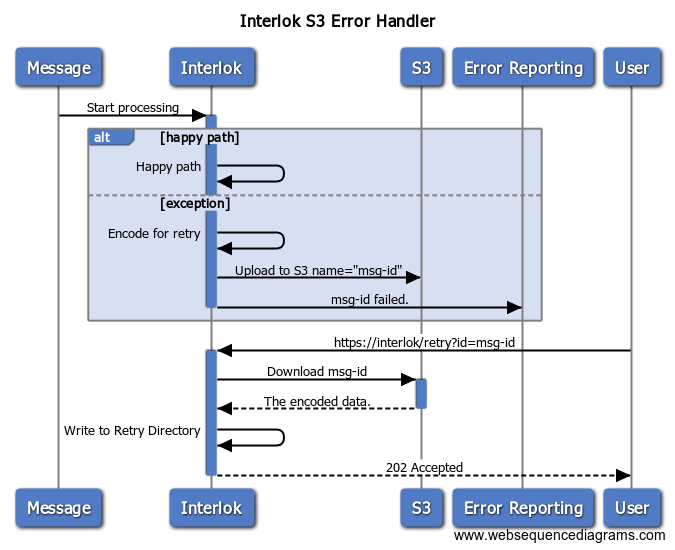
Handling the Errors
Essentially your error handling chain is similar to a normal filesystem based error chain, the only difference is that you are uploading to S3 rather writing to the filesystem.
<message-error-handler class="standard-processing-exception-handler">
<unique-id>S3+HTTP_500</unique-id>
<always-handle-exception>true</always-handle-exception>
<processing-exception-service class="service-list">
<services>
<generate-unique-metadata-value-service>
<metadata-key>error-id</metadata-key>
<generator class="guid-generator"/>
</generate-unique-metadata-value-service>
<encoding-service>
<encoder class="mime-encoder"/>
</encoding-service>
<amazon-s3-service>
<connection class="shared-connection">
<lookup-name>shared-amazon-s3</lookup-name>
</connection>
<operation class="amazon-s3-upload">
<bucket-name class="constant-data-input-parameter">
<value>${amazon.s3.bucket}</value>
</bucket-name>
<key class="constant-data-input-parameter">
<value>interlok/%message{error-id}</value>
</key>
</operation>
</amazon-s3-service>
<exception-report-service>
<exception-serializer class="exception-as-json-with-stacktrace"/>
</exception-report-service>
<!-- Insert your own error reporting system here -->
<standalone-producer>
<producer class="jetty-standard-response-producer">
<status-provider class="http-configured-status">
<status>INTERNAL_ERROR_500</status>
</status-provider>
<content-type-provider class="http-configured-content-type-provider">
<mime-type>application/json</mime-type>
</content-type-provider>
<send-payload>true</send-payload>
</producer>
</standalone-producer>
</services>
</processing-exception-service>
</message-error-handler>
In this specific instance the following things happen:
- Generate a new unique id which is used as the filename in the S3 bucket; we did this so that you can have a record of all the errors, if the workflow is complex then it might fail in different places.
- Encode the data using
mime-encoder: this preserves the workflowId where the message failed (the retrier uses this to figure out how to retry the message) - Upload the encoded message to S3.
- Report the error back to the caller (in this case a HTTP 500 error with a jsonified stacktrace)
- Bonus error reporting using something like rollbar?
Triggering a retry
This is basically the reverse of the error handling, having written to the filesystem, you can wait for a standard failed message retrier to kick in.
- Figure out the message we want to download from S3.
- Download it from S3.
- Write it out to the filesystem in the expected directory for the failed message retrier.
- we don’t need to encode it, because it’s already encoded.
<standard-workflow>
<unique-id>CopyToRetry</unique-id>
<consumer class="jetty-message-consumer">
<unique-id>/retry</unique-id>
<destination class="configured-consume-destination">
<destination>/retry/*</destination>
<configured-thread-name>CopyToRetry</configured-thread-name>
</destination>
<parameter-handler class="jetty-http-parameters-as-metadata"/>
<header-handler class="jetty-http-headers-as-metadata"/>
</consumer>
<service-collection class="service-list">
<services>
<!-- assume http://localhost:8080/retry?errorId=XXXX -->
<amazon-s3-service>
<connection class="shared-connection">
<lookup-name>shared-amazon-s3</lookup-name>
</connection>
<operation class="amazon-s3-download">
<bucket-name class="constant-data-input-parameter">
<value>${amazon.s3.bucket}</value>
</bucket-name>
<key class="constant-data-input-parameter">
<value>interlok/%message{errorId}</value>
</key>
</operation>
</amazon-s3-service>
<standalone-producer>
<producer class="fs-producer">
<destination class="configured-produce-destination">
<destination>${adapter.retry.dir.url}</destination>
</destination>
<fs-worker class="fs-overwrite-file"/>
<create-dirs>true</create-dirs>
</producer>
</standalone-producer>
<standalone-producer>
<producer class="jetty-standard-response-producer">
<status-provider class="http-configured-status">
<status>ACCEPTED_202</status>
</status-provider>
<response-header-provider class="jetty-no-response-headers"/>
<content-type-provider class="http-raw-content-type-provider">
<content-type>text/plain</content-type>
</content-type-provider>
<send-payload>false</send-payload>
</producer>
</standalone-producer>
</services>
</service-collection>
</standard-workflow>
A full adapter that contains the logic can be found here. Trigger the /fail endpoint with any data that you want, and make a note of the error-id (check for it in the S3 bucket). Use that error-id when posting back to the /retry endpoint, and you will the message fail again, and another message appear in your S3 bucket.