Since 3.9.1
This guide will walk you from zero knowledge of Interlok and Kubernetes all the way through to deploying an instance of Interlok into a Kubernetes scaling pod in around 15 minutes.
If you happen to be amazing, working on another operating system other than Windows 10 pro, or already have a Kubernetes installation, your commands throughout this guide may change slightly. If you are one of those people, we assume your awesomeness can carry you through the first few sections of installation and set-up, which you can blithely ignore.
Assumptions
We are assuming a few things here;
- You are on a Windows 10 professional system
- HyperV has been enabled on your windows system
- You have Admin access
- Every time we ask for a “command line” it is also assumed you will run the command line with elevated privileges (as admin! every time!). If you hit errors along the way, this is the first thing to check.
- You have docker installed.
- You have have GIT installed.
Pre-requisites
With the assumptions above, you will need to install the following software;
- chocolatey
- helm
- jmeter
Chocolatey
Chocolatey is a tool for Windows that allows you to install/manage packages easily with a simple command; no need for browser searching and handling installers or zip files.
Open a command line (with admin access). Hit your windows key and type “cmd”, then right click the command line app and choose run as administrator (this is the last time we’ll remind you to open a command line with admin access).
Then simply copy and paste the following (every character) into the command line and hit enter;
@"%SystemRoot%\System32\WindowsPowerShell\v1.0\powershell.exe" -NoProfile -InputFormat None -ExecutionPolicy Bypass -Command "iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))" && SET "PATH=%PATH%;%ALLUSERSPROFILE%\chocolatey\bin"
Helm
Helm is the default tool used by many dev-ops administators to install packages directly into Kubernetes. We’ll use chocolatey to install Helm. On your command line type the following;
choco install kubernetes-helm
Now make sure Helm is on your PATH. Skip the rest of this if you know what I’m talking about. Again on your command line (you will need a new command line), type;
helm version
If you get an error then add Helm to your path.
To do this, you’ll need to type “System” into the windows search bar and hit enter.
On the left hand side click the “Advanced System Settings” link.
In the new window, click the “Environment Variables” button.
In the lower pane, scroll down until you find the “PATH” variable. Double click it!
Add a new entry and simply type the directory to your Helm install; which will likely be;
C:\ProgramData\chocolatey\lib\kubernetes-helm\tools\windows-amd64
JMeter
In this guide we’ll be using Interlok as a web server. Therefore we’ll expose an endpoint that we will need to hit with load to force the Kubernetes engine to trigger scaling for the interlok instance.
The following link will start a zip download of Apache JMeter;
http://apache.mirrors.nublue.co.uk//jmeter/binaries/apache-jmeter-5.1.1.zip
Once downloaded, unzip to your preferred directory, example; C:\tools\apache-jmeter
Setup Windows
We need to do two things;
- Create a new network switch
- Install minikube and kubectl
A new network adapter
The new network switch/adapter will allow minikube to share your internet connection. Much like a virtual network, we will use power shell with a couple of commands and create a dedicated network adapter.
Hit the windows key and type “powershell”, then make sure you right click the powershell app and choose “Run as Administrator”, it will not work otherwise!
Once the blue command line appears in front of you, type the following;
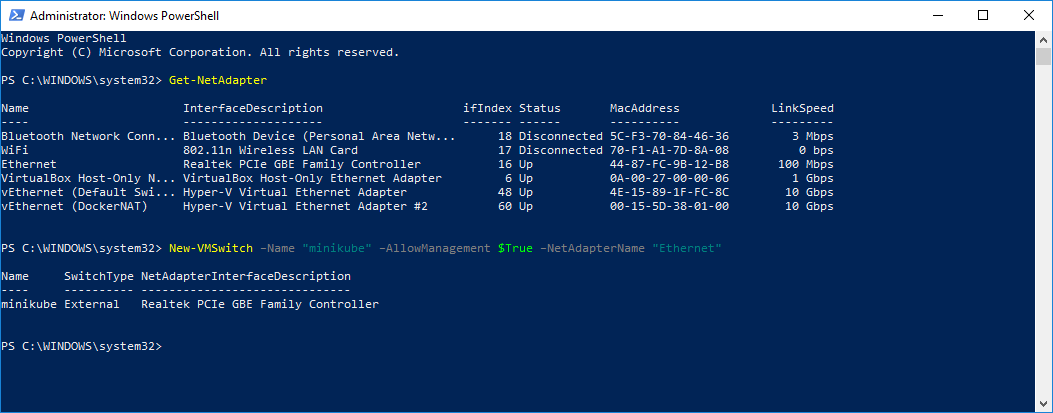
> Get-NetAdapter
That will list the current network adapters installed on your machine. You will now need to select one of them; ideally you’ll choose your ethernet hard connection or wifi connection, whichever you happen to use for your primary internet access. Highlight and copy the name of the adapter.
Then back on the powershell command line type the following (replacing the “
New-VMSwitch –Name "minikube" –AllowManagement $True –NetAdapterName "<network-adapter>"
This will create you a new dedicated network adapter just for minikube!
It will also name your new network adapter “minikube”. If you choose a different name, make a note of it for later.
Install minikube and kubectl
Minikube allows us to run a Kubernetes cluster locally. Kubectl is the command line tool we use to interact with kubernetes (minikube in this instance).
It’s choco time
Open a command line prompt (remember the rules from above, must be run as admin - always!); We’re going to use “chocolatey” to install the required packages;
choco install minikube kubernetes-cli
You may have to wait a few moments before everything is downloaded and installed. Follow any on screen instructions.
Now add both of these to your Windows path. Explained above.
Here’s where we actually get started
The above is purely setup. Once it’s all done, there’s no need to re-do it again. From now on, if you ever need to recreate this environment, skip the above and continue from here.
Let’s start our Kubernetes cluster and actually do some cool stuff!
Start Kubernetes
In one of the setup sections above you will have created a new network adapter and given it a name. I called mine “minikube” and if you copy pasted my commands you will have called yours the same, if you called yours something else, then replace “minikube” below for your network adapter name;
> minikube start --vm-driver=hyperv --hyperv-virtual-switch=minikube
This command will force minikube to start under hyper-visor (HyperV) and will make use of the new network switch, in our case named “minikube”.
Note, it may take as long as five minutes to complete, depending on…. well stuff.
Once the command line comes back to you without errors, congratulations you now have a Kubernetes cluster running locally. Let’s go do some cool stuff!
Validate your install (a must!)
Should be a once only job, but it’s necessary…
If like me you have docker desktop installed then you will also have “kubectl” as part of that installation. Docker desktop uses an older version of kubectl, so we need to make sure we’re using the correct versions! Open a command line.
Execute the following on the command line;
> kubectl version
What you’re expecting is two lines to come back from this command; one for the server and the other from the client. Hopefully they’re both the same version. If the client is of a lower version, then it is probable that you are using the docker desktop version of kubectl.
If this is the case, then you need to make sure the first(!) entry in your PATH is the choco installed version of kubectl.
If you have followed these instructions verbatim, then see the above instructions on how to edit your PATH environment variable in the Helm section. Make sure to add a new entry at the very top(important!) of the list to your chocolatey installation of kubectl, which will likely be found here;
C:\ProgramData\chocolatey\lib\kubernetes-cli\tools\kubernetes\client\bin
If you need to rerun the “kubectl version” (in a brand new!) command line prompt, here is the output you’re looking for;
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.0", GitCommit:"e8462b5b5dc2584fdcd18e6bcfe9f1e4d970a529", GitTreeState:"clean", BuildDate:"2019-06-19T16:40:16Z", GoVersion:"go1.12.5", Compiler:"gc", Platform:"windows/amd64"}
Server Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.0", GitCommit:"e8462b5b5dc2584fdcd18e6bcfe9f1e4d970a529", GitTreeState:"clean", BuildDate:"2019-06-19T16:32:14Z", GoVersion:"go1.12.5", Compiler:"gc", Platform:"linux/amd64"}
At time of writing the latest versions were 1.15.0. Your’s may be different, just ensure the reported versions match as mine do above. Both server and client report 1.15.0.
Helm is the package management tool of choice for Kubernetes.
To be able to use Helm, the server-side component tiller needs to be installed on your cluster.
Install Tiller on the Cluster
Helm installs the tiller service on your cluster to manage charts.
Since RBAC (Role-based access control) is enabled by default we will need to use kubectl to create a serviceaccount and clusterrolebinding so tiller has permission to deploy to the cluster.
-
Create the ServiceAccount in the kube-system namespace.
-
Create the ClusterRoleBinding to give the tiller account access to the cluster.
-
Finally use helm to install the tiller service
> kubectl -n kube-system create serviceaccount tiller
> kubectl create clusterrolebinding tiller \
--clusterrole=cluster-admin \
--serviceaccount=kube-system:tiller
> helm init --service-account tiller
NOTE:
This tiller install has full cluster access. Check out the helm docs for restricting tiller access to suit your security requirements.
Test your Tiller installation
Run the following command to verify the installation of tiller on your cluster:
> kubectl -n kube-system rollout status deploy/tiller-deploy
Waiting for deployment "tiller-deploy" rollout to finish: 0 of 1 updated replicas are available...
deployment "tiller-deploy" successfully rolled out
And run the following command to validate Helm can talk to the tiller service:
helm version
Install Prometheus
Very easy. We’ll use Helm to install the Prometheus operator, push-gateway, alert-manager and server with a simple command line;
helm install stable/prometheus --name prometheus --namespace monitoring
If you’re familiar with Kubernetes namespaces then know we’re installing Prometheus into the “monitoring” namespace. If not, then don’t worry and blithely follow the rest of the guide.
If you change anything above then it will have an impact on the later steps. If you have changed anything it’s assumed you know what you’re doing and no support is given.
It may take a minute or so before all Prometheus pods are up and running.
You can check by executing the following command and checking the readiness output;
> kubectl get pods -n monitoring
Install Interlok
At time of writing we do not have a Helm chart for installation, although this is planned for the near future. For now we’ll use the standard Kubernetes deployment yaml.
You’ll need to clone the following public GIT project;
https://github.com/adaptris-labs/interlok-kubernetes-scaling.git
This git project includes all of the configuration files needed to reach the end of this guide.
Once cloned you’ll need a command line and change directory into this cloned project. (If anything fails, it’s probably because you didn’t open an elevated command line; you were warned!).
Now we’ll install an instance of Interlok, with the following (assuming your command line is in the newly cloned project root);
C:\workspace\interlok-kubernetes-scaling>kubectl create -f create-interlok.yaml
Given a moment or two, this will start an instance of Interlok in the “default” namespace that has been setup to essentially be a web-server. It listens to any communications coming in on port 8080 at the endpoint “/in-box”. To test that interlok is up and running you can make sure you can access the WebUI below…
Test Interlok locally
This requires two steps. The first is to port-forward 8080 from the the interlok pod and the second is to launch a browser and navigate to “http://localhost:8080”.
Once Interlok is up and running which you can check with the following command;
> kubectl get pods
Assuming you see the pod is running, then you can port-forward the web server (you may wish to do this in a separate command line, because further input into the command line will be blocked while port-forwarding is running);
First step is to get the name of the Interlok pod and copy it to your clip board;
> Kubectl get pods
Given the name of the pod which may be something like “interlok-sakjfdh8fcy9sa3”, simply replace the “podname” below with the actual name.
> kubectl port-forward podname 8080
Now you can use your browser to navigate to “http://localhost:8080” and have access to the Interlok UI.
Load Interlok up with JMeter
Our Interlok configuration has a single HTTP consumer, that simply returns any http request with a 200 OK. If you followed the above sections, then you can have a look at the very simply configuration through the Interlok UI.
What we’ll do now is pump some messages into Interlok (requires the port-forwarding above). Open up Apache JMeter. Then using the “Open” option from the “File” menu, navigate to the git clone from above and select the file “load.jmx”.
This is a pre-built Apache JMeter configuration that lets you inject message straight into your Interlok instance. Simply click on the “Thread Pool” node on the left in JMeter and modify the “Loop Count” to any number you want; when we say any number, lets keep it below 100 for now.
** Optional **
If you want to follow the Interlok logs as each message is processed then this can be done with the following two commands.
The first gives you the full name of the interlok pod. Copy it to your clip board after the output from the following command;
kubectl get pods
Then you can connect to the Interlok pod and follow the logs as they appear with the following (replace podname with the name of your actual Interlok pod name from above);
kubectl logs podname -f
The “-f” means “follow”. Your command line will update with the latest logging as new log lines are created.
Wait a few moments and fire some more messages into Interlok with a different number.
The importance of this is simply that Prometheus doesn’t know about our custom Interlok metrics until they are sent. By generating messages into Interlok, we will be sending those metrics into Prometheus.
** Also optional **
The next step is checking the metrics now exist in Prometheus.
The first step is to gain access to the Prometheus server through port-forwarding.
Get the name of the Prometheus server;
kubectl get pods -n monitoring
Copy the name of the “server” component. Then port-forward port 9090, replacing “podname” for your actual Prometheus server’s pod name;
kubectl port-forward -n monitoring podname 9090
Now you can point your browser at “http://localhost:9090”.
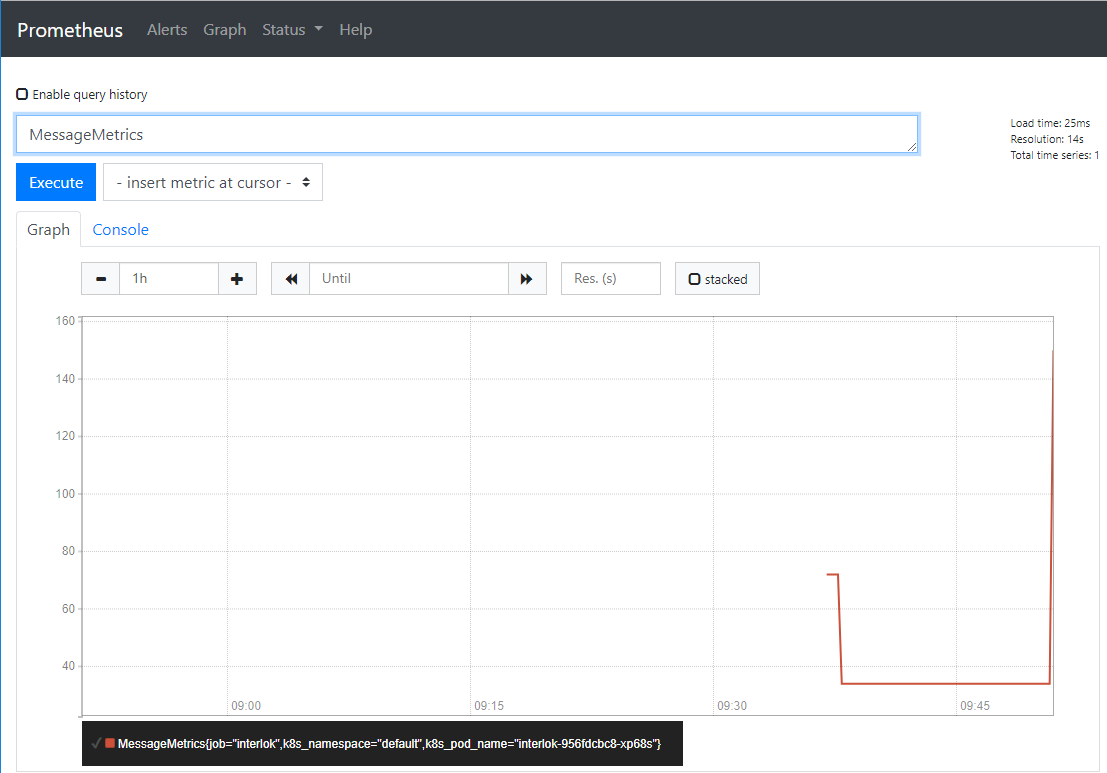
You’ll be presented with the Prometheus dashboard, type “MessageMetrics” into the query field and hit “Execute”. Note, that it can take a couple of minutes for your metrics to appear.
Install the custom metrics adapter
So far, we have installed Interlok which is generating metrics and through the use of the Prometheus pushgateway is populating Prometheus with our metrics.
Now we need to make Kubernetes aware of these metrics. We do this through the Prometheus-Adapter. On your command line execute the following;
helm install --name prometheus-adapter --namespace monitoring --set prometheus.url=http://prometheus-server.monitoring.svc.cluster.local --set prometheus.port=80 stable/prometheus-adapter
If you have followed this guide without any changes, then the adapter will connect to the Prometheus server and serve metrics to Kubernetes.
The basic configuration of the adapter will not include any of the Interlok metrics, so we need to modify the configuration.
The Prometheus-Adapter documentation suggests we can modify the install command above to include our own custom rules.
But to continue the idea of not needing any knowledge of these technologies, we’ll show you another way to edit the configuration, which comes in two steps.
Edit the adapters ConfigMap
On your command line enter the following;
kubectl edit ConfigMap -n monitoring prometheus-adapter
Depending on your operating system a new text editor will appear with the default adapter configuration. It may look something like this;
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
data:
config.yaml: |
rules:
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters: []
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[5m]))
by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_seconds_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}[5m]))
by (<<.GroupBy>>)
- seriesQuery: '{__name__=~"^container_.*",container_name!="POD",namespace!="",pod_name!=""}'
seriesFilters:
- isNot: ^container_.*_total$
resources:
overrides:
namespace:
resource: namespace
pod_name:
resource: pod
name:
matches: ^container_(.*)$
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>,container_name!="POD"}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_total$
resources:
template: <<.Resource>>
name:
matches: ""
as: ""
metricsQuery: sum(<<.Series>>{<<.LabelMatchers>>}) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters:
- isNot: .*_seconds_total
resources:
template: <<.Resource>>
name:
matches: ^(.*)_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[5m])) by (<<.GroupBy>>)
- seriesQuery: '{namespace!="",__name__!~"^container_.*"}'
seriesFilters: []
resources:
template: <<.Resource>>
name:
matches: ^(.*)_seconds_total$
as: ""
metricsQuery: sum(rate(<<.Series>>{<<.LabelMatchers>>}[5m])) by (<<.GroupBy>>)
kind: ConfigMap
metadata:
creationTimestamp: "2019-07-26T15:12:23Z"
labels:
app: prometheus-adapter
chart: prometheus-adapter-1.2.0
heritage: Tiller
release: prometheus-adapter
name: prometheus-adapter
namespace: monitoring
resourceVersion: "23090"
selfLink: /api/v1/namespaces/monitoring/configmaps/prometheus-adapter
uid: c530fde2-9314-4b15-8ff7-7da4df2e3b7b
You may notice in yaml format a list of “seriesQuery”’s. Each of these series queries details how to find metrics in Prometheus that Kubernetes should be aware of.
We need to add our own series query to make sure Kubernetes can make use of Interlok metrics.
We will add the following yaml block to the list of series queries;
- seriesQuery: '{__name__=~"MessageMetrics"}'
resources:
overrides:
k8s_namespace:
resource: namespace
k8s_pod_name:
resource: pod
name:
matches: ""
as: "MessageMetrics"
metricsQuery: MessageMetrics
A more detailed explanation of each line can be found both later on in this guide in the “Further Information” section or by reading the Prometheus adapter documentation, linked above.
Be careful to make sure your series query above is pasted just before the line reading; “kind: ConfigMap”. Also be sure to make sure your indentation follows the other series queries.
Hit “save” on your text editor and then simply close it down. The “kubectl edit” command will recognise you have closed the text editor and automatically save the ConfigMap changes for you.
Restart the adapter
Now we need to restart the prometheus adapter pod to force a re-read of the configuration. First you’ll need the name of the adapter pod;
kubectl get pods -n monitoring
You’re looking for the pod name beginning with “prometheus-adapter…”
Copy the name and run the following command replacing “podname” with the actual adapters pod name from above;
kubectl delete pod -n monitoring podname
This will force the pod to be deleted and in it’s place in a few moments a new one will launch. The new one however will have loaded our updated configuration.
Note: There is a known issue with the prometheus-adapter, that it can have issues while running.
Specifically, that it tends to restart many times. There seems to be a timing issue with the readiness probe. If you have any errors with the following commands, simply wait a minute or so for the adapter to sort itself out and try again (which it tends to do, but can take a minute or so).
You can check the health of the adapter pod by listing all pods in the “monitoring” namespace, the command for which has been shown several times above.
Optional - check the metrics are available to Kubernetes
On your command line execute the following after a couple of minutes of the adapter running;
kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pod/*/MessageMetrics > metricsInterlok.txt
This command will query the newly created custom.metrics api (Prometheus-adapter) for the current metric value of our Interlok metric named “MessageMetrics” and save the result in a file named “metricsInterlok.txt”.
You should expect to find something like the following;
{
"kind":"MetricValueList",
"apiVersion":"custom.metrics.k8s.io/v1beta1",
"metadata":{
"selfLink":"/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pod/%2A/MessageMetrics"
},
"items":[
{
"describedObject":{
"kind":"Pod",
"namespace":"default",
"name":"interlok-956fdcbc8-xp68s",
"apiVersion":"/v1"
},
"metricName":"MessageMetrics",
"timestamp":"2019-07-29T09:46:49Z",
"value":"34"
}
]
}
In the “items” section you should see the last number of messages we pumped into Interlok via JMeter. In the example case above, the value is 34.
If however you do not receive any items at all, then simply push a few more messages into Interlok via JMeter, wait a few moments and try the command again.
If you receive an error from this command along the lines of “server unavailable” then you are suffering from the Prometheus adapter restarting itself. You might just have to wait until it’s back up and running.
Install the Interlok HPA
This is the final step of required configuration. The HPA is the “Horizontal Pod Autoscaler”. This is responsible for configuring how many instances of Interlok you would prefer to be running at a minimum and how many after scaling you want as a maximum. It also lets us configure the trigger for scaling; in other words for our example, after how many messages are processed should we start scaling up.
On your command line (assuming you are in your git cloned project as mentioned above);
kubectl create -f autoscale-interlok.yaml
After a moment or two, you can take a look at the details for the autoscaler;
kubectl describe hpa
Considering we only have one horizontal pod autoscaler, you can get away with the above command, if you happen to have multiple HPA’s in your environment you may need to specify the name of the autoscaler, which in our example is called; “interlok-autoscaler”.
You’ll see some interesting statistics in the output, which might if the metrics API has not had a chance yet to analyze the stats show values of “unknown”. Given a little time, you’ll see the autoscaler has discovered our interlok metrics and has decided not to scale yet.
The HPA we just installed says, if we are processing more than 100 messages then please autoscale us.
Using JMeter fire 150 messages into Interlok
Then wait a moment and “describe” the HPA again (command above). You’ll see something like this;
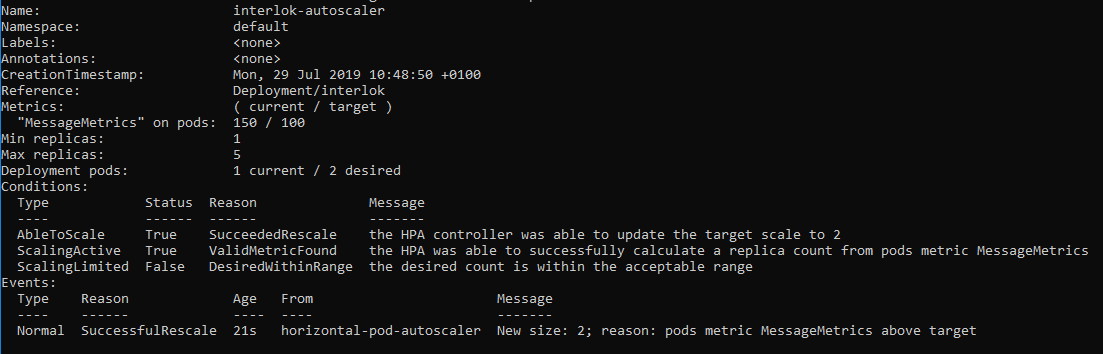
From the output we can see the “Deployment pods” says we currently have 1, but we desire 2. This is because our 150 messages have broken through the 100 messages boundary. We can also see in the final line, that Kubernetes has decided we need two(!) instances of Interlok due to the maximum message boundary being broken.
Now if we do a quick look at the number of pods running in the default namespace we should see two instances of Interlok;

We have just been autoscaled.
Further Information
The walk-through is complete, but now you either want a more visually pleasing experience or you want to know how all of this actually works… keep reading.
Graphana for stunning visuals
Graphana is the go to visualization component for Prometheus. You’ll see the difference shortly from the Prometheus dashboard screenshot above.
To install Graphana into the monitoring namespace, we’ll execute the following;
helm install stable/grafana --name graphana --namespace monitoring
Then we need to log into and configure the dashboard, which requires four steps; getting access to the admin password, port-forwarding the port 3000, logging in through our browser and finally configuring the Prometheus data source.
The password
To get the Graphana password, base64 encoded do the following;
kubectl get secret --namespace monitoring graphana-grafana -o jsonpath="{.data.admin-password}"
The raw output from this command needs to be base64 decoded, if you happen to have a base64 decoder through your command line, then great, pipe the output of this command into that decoder tool.
If not, then simply use a free online base64 decoder. The result in either case is your new admin password.
Port-Forward 3000
First get the name of your Graphana pod;
kubectl get pods -n monitoring
Then do the port-forward;
kubectl port-forward -n monitoring graphanaPodName 3000
Login through your browser
Navigate to “http://localhost:3000”. Type “admin” as your username and the base64 decoded password from above.
Configure the data source
Hit the “Add Data Source” button and choose “Prometheus” from the list of available providers.
The only field you need to modify now is the Http Url. If you’ve followed this guide to the letter you can simply enter; “http://prometheus-server:80”.
Now hit the “Save and test” button.
On the left, choose “Dashboards” and from the context menu choose “Manage”.
Create a new dashboard.
Hit the “Add Query” button and copy the below configuration;
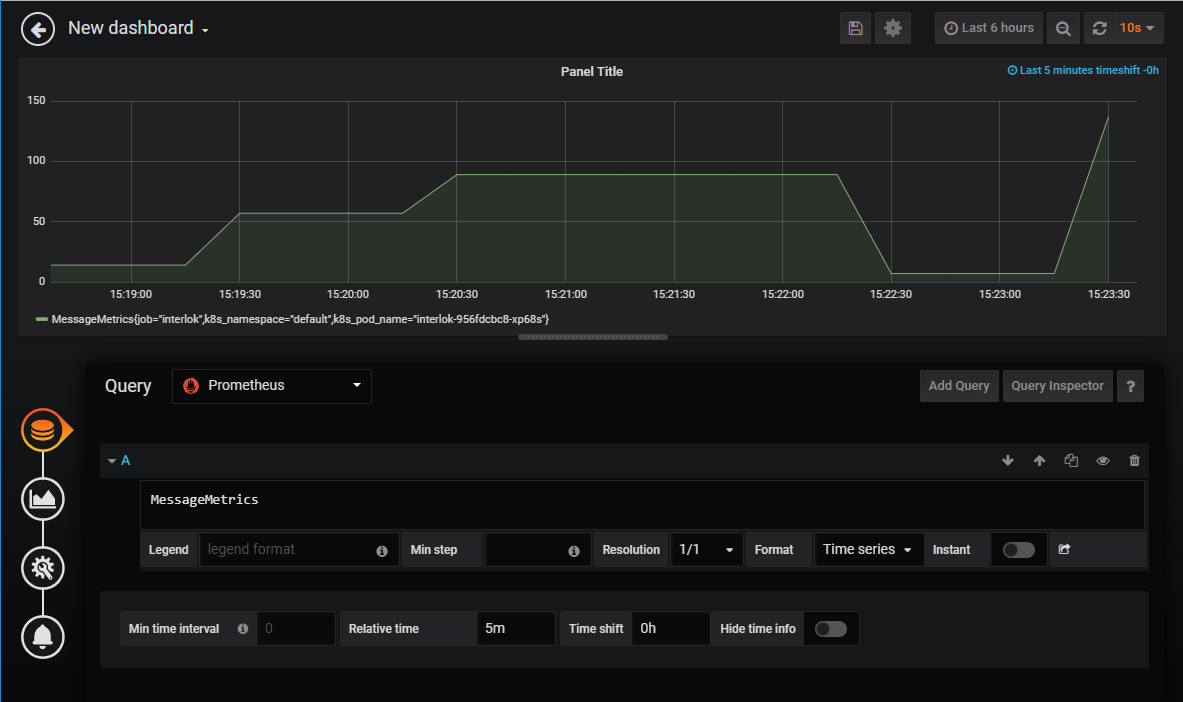
This graph shows the value of the Interlok “MessageMetrics” metric in the last 5 minutes. Feel free to shove more messages into Interlok through JMeter and keep an eye on the graph.
How does it all work?
That’s a big question and has been broken down into a few sections below.
How are Interlok metrics generated?
Every time you start an instance of Interlok, every workflow will by default have a message-metrics-interceptor. You don’t need to configure one, we’ll do it for you. But you can configure one for each workflow if you want. The name of the interceptor is very important!
Take a look at the following interceptor configuration for our example config we have used in this guide;
<message-metrics-interceptor>
<unique-id>MessageMetrics</unique-id>
<timeslice-duration>
<unit>SECONDS</unit>
<interval>5</interval>
</timeslice-duration>
<timeslice-history-count>100</timeslice-history-count>
</message-metrics-interceptor>
Notice the name of the interceptor is also the name of our published metric.
How do Interlok metrics make their way to Prometheus
Through the Prometheus pushgateway.
There are basically two ways, this can be done; the first is by exposing a http url to Prometheus that will periodically scrape that url for available metrics.
We chose not to do this, simply because we advise not to use the embedded web server if you really don’t need it for each Interlok instance.
Therefore, because the embedded web server may not be available, we use the pushgateway, which allows us to SEND metrics to Prometheus on a regular interval and therefore no need for extra scraping configuration. All you need to know is the pod’s host name and port number of the Prometheus server, then you simply configure the deployment configuration ( in this guide known as create-interlok.yaml);
apiVersion: apps/v1
kind: Deployment
metadata:
name: interlok
labels:
app: interlok
spec:
selector:
matchLabels:
app: interlok
template:
metadata:
labels:
app: interlok
spec:
containers:
- name: interlok-container
image: aaronmcgrathadpx/interlok-kubernetes-scaling:latest
ports:
- containerPort: 5555
- containerPort: 8080
env:
- name: JAVA_OPTS
value: -DprometheusEndpointUrl=prometheus-pushgateway.monitoring.svc.cluster.local:9091 -Dnetworkaddress.cache.ttl=30
- name: K8S_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: K8S_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
There are three important properties that are set here for Interlok to send generated metrics;
The first is overriding the JAVA_OPTS with the “prometheusEndpointUrl”. This tells Interlok how to reach the metric server. The next two properties are environment properties that will be populated by the Interlok deployment instances namespace and pod name.
These must always appear in any Interlok deployment that wishes to send meaningful metrics to Prometheus.
You see using the pushgateway, we must tell Prometheus the name of the namespace and the full pod-name of each instance that we are publishing metrics for.
Ok, we’ve sent metrics, how do they match up with the autoscaler?
This is where the Prometheus-adapter comes in. Although a far more detailed explanation can be found on the prometheus adapters github project, lets take another look at the series query we added to that configuration;
- seriesQuery: '{__name__=~"MessageMetrics"}'
resources:
overrides:
k8s_namespace:
resource: namespace
k8s_pod_name:
resource: pod
name:
matches: ""
as: "MessageMetrics"
metricsQuery: MessageMetrics
The first line tells the adapter what to search for in Prometheus to get a list of available metrics. We’re using a regular expression, but for our simple example, we could have just had “MessageMetrics” as the value here. The resources are the important part. You must combine a metric with a given Kubernetes resource. Remember the Interlok deployment config above? That gives Interlok the envionrment variables to get the current instances namespace and pod-name. Interlok uses those to add labels to the metrics it pushes to the pushgateway.
In fact if you query Prometheus for “MessageMetrics” you’ll get something like this back;

Notice how we have the metric name, followed by key-value pairs.
| Key | Value |
|---|---|
| job | interlok |
| k8s_namespace | default |
| k8s_pod_name | interlok-……. |
Our series query block above tells the adapter how to translate the key-value pairs into actual Kubernetes resources. It simply says, the value of the key “k8s_namespace” is the actual namespace of the deployment. It also says the value identified by the key “k8s_pod_name” is the full name of the interlok pod.
With resources set, Prometheus and Kubernetes HPA (horizontal pod autoscaler) know exactly which resource these metrics came from; in our example case the Interlok pod instance we launched.
Now take our autoscaler;
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: interlok-autoscaler
namespace: default
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: interlok
minReplicas: 1
maxReplicas: 5
metrics:
- type: Pods
pods:
metricName: MessageMetrics
targetAverageValue: 100
It simply says, look for any metrics named “MessageMetrics”. If the average value (from all Interlok pod instances) goes above 100, we need to scale up. We also don’t want to scale more than five instances of Interlok.
This has been a very simple auto-scaling guide on a single metric. Playing around with the Prometheus adapter configuration and auto-scaler allows you to do some quite powerful queries and calculations, so that you can scale from multiple metrics and time slices. It’s beyond the scope of this document to go any further however, but know that you have now been introduced to the auto-scaling capabilites of Interlok within Kubernetes.